Migration Strategies and Considerations Guidelines
Currently, there is no migration tool available to move your self-managed clusters to HCP Vault.
If you have self-managed Vault clusters and wish to move your data to the HashiCorp Cloud Platform (HCP) Vault, there are migration strategies and considerations to keep in mind. This document covers a few of the migration scenarios and examples that can help you prepare to transition from your self-managed clusters to a hosted platform.
Migration Planning
Migrating data from an existing Vault cluster to another requires a well-thought plan. However, the advantages of moving from a self-hosted deployment platform to HCP Vault are significant, including the opportunity to redesign your Vault implementation and workflows to match your organization's rate of scale. The planning process also provides you with opportunities to understand and address any points of friction or contention that developers may experience with Vault.
To help you and your organization adopt a smooth migration path, the following are recommendations comprising several different phases.
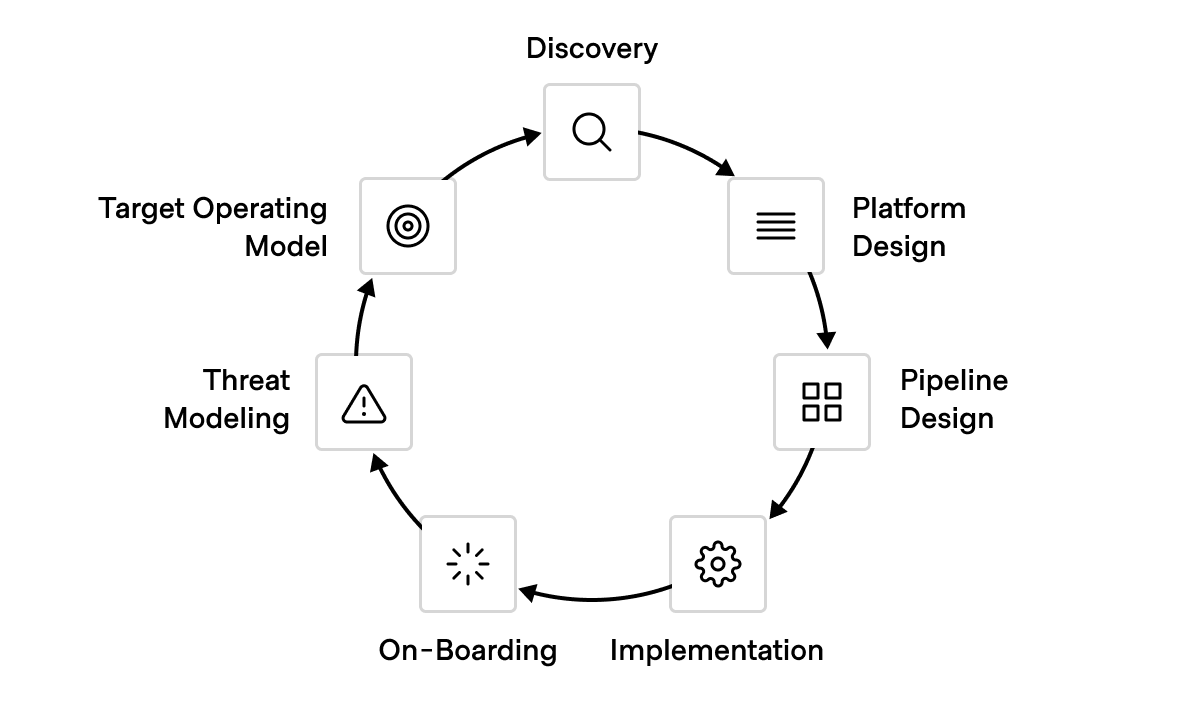
The phases include:
- Discovery
- Platform design
- Pipeline design
- Implementation
- On-Boarding
- Threat modeling
- Target Operating Model
Discovery
During the discovery phase, identify the key stakeholders within your organization to understand how they use Vault. Using business analysis techniques such as workshops and interviews to shadow the teams may offer valuable insights into the types of challenges experienced by your teams. Take note of those challenges and leverage them to make necessary changes as you migrate. In addition, work with the information security function within your organization to conduct a preliminary threat modeling exercise.
Platform Design
In this next phase, leverage the information collected during the Discovery phase to identify patterns and shared requirements across teams. You should be able to collect information, such as the following:
This information helps you identify the everyday use cases and other cases that may fall outside of the conventional scenarios and assists you in the redesign of current solutions to fit your organizational needs. We suggest gathering constant feedback from the stakeholders and keeping your teams informed of your proposed changes and recommendations during each redesign step until you reach a team consensus.
Pipeline Design
Once you complete the information-gathering tasks described in the Discovery and Platform Design phases, you should be ready to move to the next stage of planning, which is designing the pipeline that deploys Vault configuration. First, store your configuration based on new requirements and workflows in a version control system. Ensure that, based on new workflows and process details discovered, you preserve the security and integrity of the pipeline to include the following:
- Branching strategies
- Environment Promotion strategies
- Quality gates
- Testing strategies
- Pipeline ownership
- Code integrity gates
Implementation
During this phase, writing the code, policies and modules may begin. It's also essential to ensure that quality tests are written to identify gaps in the code and address any bugs identified.
On-Boarding
Before onboarding applications, we recommend that you identify early adopters. These teams, or groups of individuals, are vital in forming a successful adoption strategy and may be deemed advocates for your organization. Therefore, we suggest working with these adopters where they may assist you in determining the most appropriate services and applications by having them test the implementation locally on a development version. During this phase, you may need to tweak the design and implementation based on issues identified by the adopters. In addition, this phase provides opportunities to resolve any possible shortcomings to improve workflows and implementations.
Once testing has concluded and changes implemented, we recommend that you onboard one application at a time by working with dedicated resources from both the application team and the Vault architects/engineers.
Threat modeling
Once you have onboarded your applications to HCP Vault, the security team should conduct a threat modeling exercise based on the implementation. This exercise involves ensuring controls and processes comply with the security requirements before the final implementation. Controls include:
- Detective
- Preventive
- Corrective
Target Operating Model
You may find that while current implementations work well, it's possible that your teams may outgrow the implementation and workflows as teams and organizations continue to scale and evolve. You may be required to re-examine the current design to make improvements, and the best approach to this is to use the recommended phases, as outlined above, during your organization's operational review cycles. Use these planning phases to not only prepare you and your team to migrate to HCP Vault, but also refer to it in future redesign efforts to maintain and scale your Vault implementations alongside your organization's critical business needs.
Migration Checklist
The following is a list of resources that you will need to migrate. This list is not a comprehensive list of resources. As we continue to test migration strategies, we will continue to update this list.
- Namespace Migration
- Auth Methods
- Roles/Permissions
- Secrets Engines
- Static Secrets
- Policies
- Cryptographic Keys
- Terraform Provider Migration
Migration Considerations
These migration considerations are essential if you plan to transition your Vault data to HCP Vault. In addition, we are currently hard at work testing other migration scenarios and will update this list as additional considerations are discovered.
- Everything must be nested within the
/adminnamespace and nothing can run at the root namespace. - You cannot run anything under the
/rootnamespace; therefore, access to the/sysAPI endpoint is limited to what is proxied through the HCP portal’s controls. - HCP Vault currently does not support ADP, Replication, and third-party plugins.
Namespace Migration
If you are a Vault Enterprise customer, you may have a namespace layout in your self-managed cluster that you wish to replicate within HCP. Everything must be configured under the /admin namespace within HCP. To do this, write a script that recursively outlines the structure of your namespaces and adds them to HCP. The below script provides an example where all namespaces and nested namespaces are moved under the /admin namespace within HCP. Notably, this migrates just the namespaces and their underlying structure to HCP, and any secrets engines, auth methods, etc. configured under each namespace will need to be migrated separately.
Example namespace migration bash script:
Auth Methods
Depending on the auth method used, configuring auth methods on HCP Vault may have varying degrees of difficulty. With the help of the Vault Terraform provider and the Vault CLI, you can easily configure several of the auth methods in the same way they were implemented on the self-managed Vault cluster. However, there are some limitations to be aware of with some of the auth methods. The HCP Vault Constraints and Known Issues documents those limitations for TLS, AWS IAM, and Google OIDC.
In most cases with auth methods, ensuring the correct pathway is critical, and everything must be placed within the /admin namespace to configure the auth methods onto HCP Vault successfully.
When observing the auth methods currently enabled on the self-managed cluster, it may be useful to utilize available read API endpoints (AWS, Kubernetes, and Okta as examples), which return configurations for auth methods. Sensitive values such as passwords, API keys, and certificates will not be returned. For nested namespaces, you will need to loop through all namespaces (using the above script for example) and run the read command under each auth method to see their respective configurations.
The following auth methods are fully validated on HCP Vault. We are currently validating additional auth methods.
Roles/Permissions
The HCP Vault role-based access control (RBAC) system accomplishes several roles/permissions setups, specifically admin-level controls and permissions. However, replicating IAM roles within HCP Vault is not straightforward, given the limited access to the data plane. Likewise, permissions set on this account apply to the entire cluster rather than to specific types of operations.
Policies may be migrated over and used as role enforcement; however, you must reconfigure them to fit within the HCP namespaces. This process can be challenging because not only are namespaces all configured within admin/, but you may want to use
nested
namespaces with
varying permissions dictated by policies. In this way, role/permission migration
isn’t trivial and requires extra work in translation.
Secrets Engines
There are some considerations to keep in mind when implementing secrets engines in HCP Vault. Currently, you must re-create your secrets engine within HCP Vault. Remember to check if the secrets engine
is currently
supported
and enabled within the /admin namespace.
If you’re instantiating the secrets engine from the terminal, most secrets engine setups follow a similar pathway to self-managed, including setting the appropriate environment variables for address and token. In addition to setting those environment parameters, it is crucial to set the environment variable for VAULT_NAMESPACE=admin; otherwise, you risk running into permission issues. Ensuring the admin namespace is included in relevant pathways is essential in ensuring a successful secrets engine setup in HCP Vault.
Similarly to auth methods, you can list out the secrets engines enabled on your self-managed cluster and subsequently read each of their configurations (AWS, KV2, and Databases as examples) in order to make replicating onto HCP easier. Again, this won’t return any sensitive values or secrets. As stated above, remember to set/change the namespace to be nested under /admin in all instances.
Most common secrets engine methods are set up similarly under the /admin pathway and used in the HCP Vault cluster. KV, AWS, Transit, and Databases are the current secrets engines that are the most compatible with HCP Vault. Other secret engines, like PKI, can be implemented without restrictions, but their configuration may be more
challenging.
Static Secrets
Currently, there is not a command to list out every secret in your Vault cluster. That means, to transfer static secrets into HCP Vault, you will need to save them locally or pull them directly from storage. After that, they can be stored or converted into a .CSV file, JSON object, etc., as long as the format is parsed via the bash script or Vault CLI. A bash script may be used in a .CSV file, looping through and adding all of the secrets. You may also use the Vault CLI in the case of a JSON object. Once the secrets have been moved locally, this should be a simple process.
Example CSV object and bash script (secrets.csv)
Example bash script using a Key/Value secrets engine:
To do this, the user must have the appropriate permissions enabled for both the self-managed cluster and the HCP Vault cluster. If self-managed, you must enable the read capability. After successfully moving your static secrets to HCP Vault, you may also want to remove the key-value pairs from the self-managed cluster; in this case, the delete capability may also need to be enabled. For the HCP Vault cluster, you will need to create and update permissions enabled.
Example self-managed policy:
Example HCP policy:
Ensure that you are logged in with the proper identity associated with the corresponding environment variables (VAULT_ADDR,
VAULT_TOKEN, and VAULT_NAMESPACE).
As always, when moving sensitive material between Vault instances, keep your CSV or JSON exports secure. As you do the migration, periodically check audit logs to note any additional secrets added since the migration began and add them accordingly.
Policies
You may migrate most policies in a similar loop to static secrets. This script will loop through all of your policies and create them within HCP Vault. Then, they are applied easily into HCP Vault with your correctly set up ideal pathways and permissions.
Currently, HCP Vault does not support Sentinel policies. Therefore, this section only applies to ACL policies at this time.
In the below example, you list out all policies in your self-managed cluster and move their names and content over to your HCP Vault cluster.
Note: While you can still set up your policies that include the ‘sys’ endpoint, the policies will not be enforced. In addition to this, for each nested namespace you would need to subsequently run the same commands for their policies to be enforced.
Example bash script to be run on self-managed cluster:
Cryptographic Transit Keys
You can migrate most keys using the export functionality. Once keys are made exportable, you cannot reverse this action, meaning they will always be exportable. You may export your keys using the transit secrets engine API in self-managed. First, change the configuration in self-managed to be exportable by creating a payload as below:
Following the creation of a payload, you may request to update your config. Then, generate a backup key and save it. To restore your key in HCP Vault, you must configure a Transit Secrets Engine first. Once you complete that step, you can restore your key to HCP Vault. Suppose you have multiple keys you wish to export. In that case, you can repeat this process that is similar to policies and static secrets. Next, run a bash script looping through all your keys that changes their respective configurations and backs them up. The same payload should apply to every key.
Example bash script to get all keys, update config and save backups, run on self-managed cluster:
Example bash script to restore on HCP Vault cluster:
If you do not wish to make your keys exportable, you can create new keys within HCP Vault. You can also do this inline via the CLI rather than creating a separate payload file.
Terraform Provider Migration
If you use Vault Terraform provider to manage and deploy a self-managed Vault cluster, it's simple to switch to HCP. First, switch to a new endpoint by pointing towards your HCP Vault cluster using its URL, token, and the /admin namespace. Then, run terraform init and terraform apply. The level of difficulty associated with this step depends on the details or extensiveness of the Terraform configuration. All of the above requirements for resources (policies under the /admin namespaces, checking if secrets engines/auth methods are validated, etc.) are also applicable when using Terraform. If you are deprecating a self-managed cluster, ensure you run terraform destroy to tear down old resources.
In order to do this, you either need to make your HCP endpoint public or the environment where Terraform is currently running must be peered or have a valid network path to your HCP cluster. There are several ways to do this (like using ECS or using TFC Agents in the case of TFCB). It is also possible to temporarily make your HCP Vault cluster URL public for the purposes of this transition, and then revert it back to private after (although this is not recommended for production clusters).
There are many things to consider when migrating from self-managed Vault Clusters to managed platforms like HCP Vault. Most migration strategies require that migration steps are performed manually in the absence of a migration tool. In addition, manual migration involves replicating some of the resources you wish to migrate or transitioning your resources with varying overhead. In contrast, we are documenting the migration scenarios and strategies recognized for migrating your Vault data successfully. We acknowledge that there are some scenarios that we have not covered here; however, we will continue to update this document as we test additional migration scenarios and collect feedback.
For more information about HCP Vault, check out our Documentation and Learn Tutorials.